今天我們來認識密碼學的一些基礎名詞
加密系統是將資訊利用密鑰加密,將密文傳輸到對方手上,在對方手上解密獲得原始文字
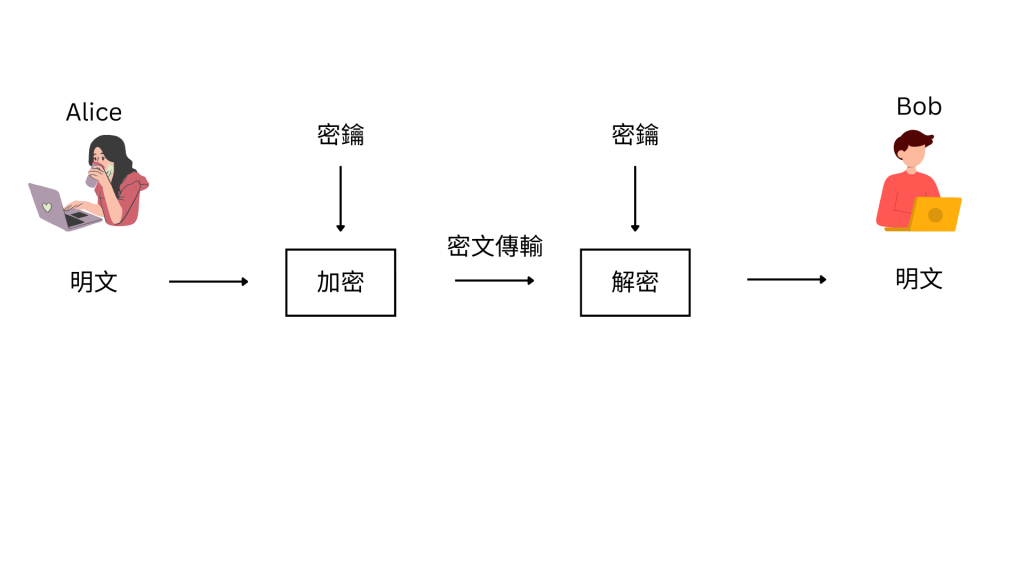
注意以上的Alice和Bob不必為人類,他們可以是用戶端與伺服器、伺服器與伺服器等
這邊用人稱抽象化可以方便我們想像
被加密的文字稱為 明文(plaintext),加密後的文字稱為 密文(ciphertext)
而 密鑰 (key)就像鑰匙,可以在Alice這將明文鎖成密文,到達目的地後能用Bob手上的另一把鑰匙還原
而鎖起來的方法有很多種,對應到不同的加密演算法
有關密鑰的使用可以區分兩種
在接下來的討論中,我們假設傳輸的通道十分不安全,密文可以很容易被Trudy攔截
(想像戰爭片中敵軍攔截無線電)
直覺來說,只要把加密所使用的演算法都隱藏起來,第三方應該就無法破解加密系統
不過事實恰好相反,一個好的加密系統需滿足 科克霍夫原則(Kerkhoff's Principle):
安全的加密演算法必須讓 所有密鑰都是可能的密鑰
即使Trudy對整個加密過程、所使用的演算法皆暸若指掌的情況下
他也只能嘗試 所有密鑰才能解開密文
只要密鑰的空間夠大,要漫無目的尋找出正確的密鑰幾乎不可能成功
也就是說,加密系統要能夠禁得起大眾審視方能堪用,否則我們都應該懷疑這個系統有安全漏洞
就歷史的演進來看,隱藏許久的加密演算法一但被公開,通常很快就會被破解,可以閱讀微軟違反科克霍夫原則
以下我們用一個例子來理解什麼是 所有可能的密鑰
這是最經典,也是最直覺的加密系統
簡單替換密碼會先制定英文字母分別對應到另外的一個字母的規則,如此將文字進行加密
舉例來說
import numpy as np
import string
np.random.seed(123)
alphabet = list(string.ascii_letters)
key = np.random.choice(alphabet, size = len(alphabet), replace=False)
alphabet中依序儲存a-z的字母
我用np.random.choice函數反覆抽取alphabet將字母順序打亂,並將此打亂的順序儲存成key
如果要跟著一起操作的讀者記得確認自己電腦的python是否有安裝Numpy
注意到我不用內建打亂順序的shuffle是因為待會alphabet和key都會用到np.random.seed(123)可以固定每次抽取的結果,如果是自己想玩的話可以把這行拿掉
code = dict(zip(alphabet, key))
decode = dict(zip(key, alphabet))
code是一個pythondict,儲存明文密文間的對應關係,decode則是將密文對應回明文
def substitute(words, codebook):
cipher = ''
for word in words:
Capital_flag = False
#檢查是否大寫
if word.isupper():
Capital_flag = True
word = word.lower()
#若不屬於英文字母,則不動
if word in key:
c = codebook[word]
if Capital_flag:
c = c.upper()
cipher += c
else:
cipher += word
return cipher
substitute函數需要提供文字以及對應的文本,這邊我為了方便將大寫字母先轉成小寫,對應過去之後再轉成大寫
print(substitute('A Big Fat Cat', code))
print(substitute('W Fms Lwk Hwk', decode))
將以上的程式碼執行一遍,我們就可以將明文A Big Fat Cat,依據key的對應關係,加密成W Fms Lwk Hwk
而手上擁有反向對應的人即可將密文W Fms Lwk Hwk還原回明文
這裡的密鑰是明文密文之間的對應關係
密鑰空間就是 所有可能的密鑰收集起來的集合
在以上的範例中,密鑰空間裡一共有 那麼多種組合
假設Trudy一秒可以猜 種對應方式,他至少得花上九百萬年才能檢查得完所有可能的密鑰
乍看之下簡單替換密碼的密鑰空間超大,要破解應該非常困難
但實際上是相當不安全的
我們明天再來說明為何不安全🤗

